Multi-cloud data & AI orchestration,
from one control plane
Polysync is a metadata-driven, multi-cloud orchestration platform that schedules, sequences, and monitors pipelines, notebooks, functions, and AI workloads across 18 cloud services across Azure, Google Cloud, and AWS today — including the latest additions for Azure AI Foundry and Azure OpenAI. The built-in Polysync Copilot answers questions about your setup and performs configuration actions for you. One workspace, one DAG engine, one monitoring view. No orchestration code to write, no separate portal for each service.
Microsoft Entra ID SSO · Per-tenant schema isolation · Admin / Operator RBAC
Why teams end up here
The patterns that keep showing up when a data platform spans more than one cloud service.
A scheduler per service
ADF triggers, Databricks jobs, Function timers, and cloud cron all live in their own portals. No shared timeline, no single source of truth for what ran when.
No dependencies across clouds
Coordinating a Databricks notebook that depends on an ADF pipeline becomes a webhook, a queue, and a long Confluence page no-one wants to maintain.
Custom glue that never stops
Every new platform adds another integration to build, secure, and keep alive. Months of engineering up front, then ongoing maintenance that follows the team forever.
No one knows what's running right now
Live status sits in each cloud's own dashboard. When something fails or stalls, the team has to log in to four tools to answer "what's queued, what just failed, and what's about to fire?"
From sign-up to first scheduled run and monitor
Three steps from subscription to a running, monitored pipeline. No bespoke orchestration code at any stage.
Connect
Link a secret vault (Azure Key Vault, AWS Secrets Manager, Google Cloud Secret Manager, or HashiCorp Vault), or let Polysync hold the credential in its managed Azure Key Vault. Register your cloud platforms, and existing pipelines, notebooks, functions, and workflows are discovered automatically with their parameters intact.
Define
Polysync is metadata-driven: a Job is the resource discovered on the platform, and a Task is a configured run of that job with parameters, schedules, and dependencies that link it to other tasks across any connected cloud. Configuration is data, not code, so there's nothing to compile, package, or redeploy when something changes.
Run & monitor
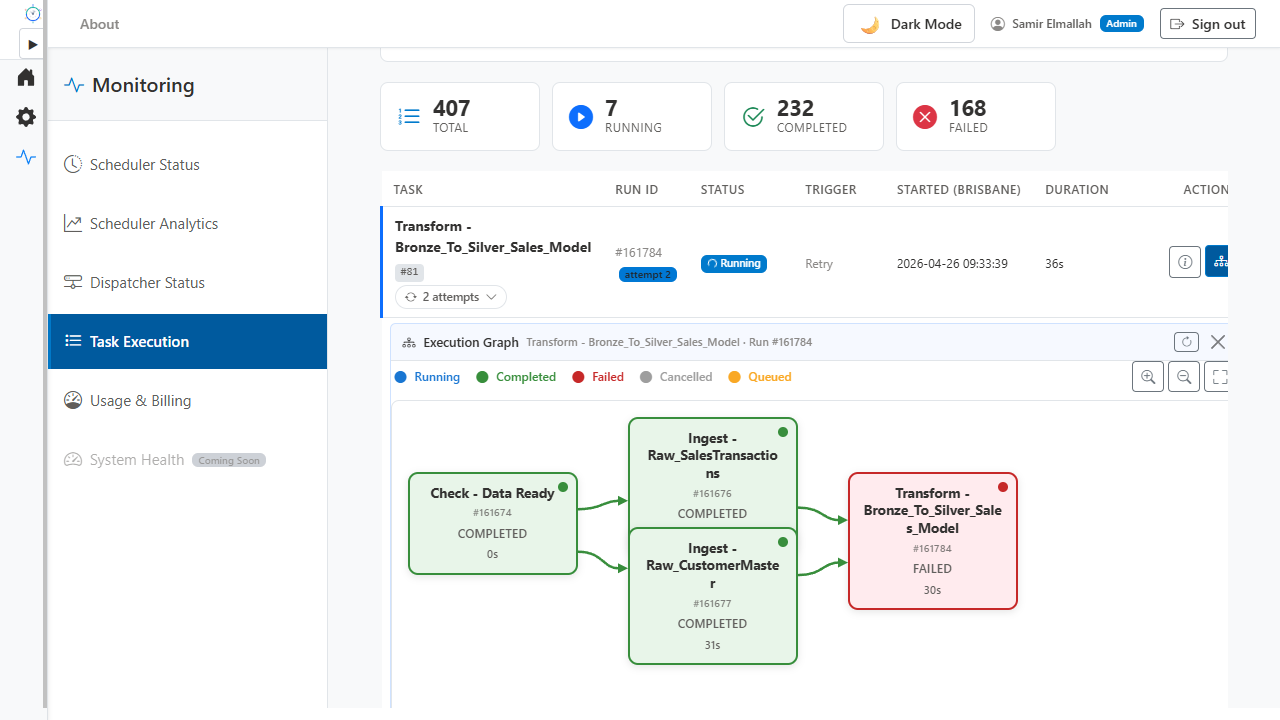
The scheduler fires cron triggers. The dispatcher resolves dependencies, enforces concurrency and rate limits, retries transient failures, and sends each task to its platform. Every run, queue, and schedule is visible in real time from a single monitoring view, with an inline DAG that shows exactly where each execution sits in the graph.
Built for production data platforms
A metadata-driven engine where jobs, tasks, dependencies, and schedules are configuration rather than code. The features that matter once orchestration leaves a developer's laptop and starts running thousands of executions a week.
DAG dependencies
Wire tasks together across platforms using On Success, On Failure, On Completion, and On Skipped triggers. If two tasks accidentally end up depending on each other, Polysync spots the loop and blocks the run before anything starts.
Concurrency & rate limits
Stop peak batch windows from tripping API throttles or overloading shared compute. Set concurrency caps (how many runs can be active at once) and rate limits using leaky-bucket or rolling-window strategies (how many runs can start per minute or hour). Apply each rule per platform or globally.
Cron scheduling with a visual builder
A full schedule editor with advanced cron syntax (seconds, ranges, steps, and named day or month tokens) paired with a click-to-build visual builder for engineers who don't want to memorise asterisks. Timezone-aware, with human-readable summaries and a next-fire preview before you save. Attach multiple schedules to one task and toggle each on or off independently.
Live monitoring
Dispatcher queue, schedule dashboard, and execution history in one view, with status filters, time-range presets, and an inline DAG that shows where each run is in the graph.
Auto-discovery
Connect a platform once. Polysync imports its pipelines, notebooks, functions, and workflows along with their parameters and configuration, so there's no manual copy-paste of metadata before you can schedule anything.
Cross-task parameter mapping
Pipe output values from a parent task into a child task's parameters, including across different clouds, without writing custom integration code in between.
Polysync Copilot
A built-in AI assistant in the Setup Studio that answers questions about your platforms, jobs, tasks, and schedules in plain English, and can perform actions on your behalf — create jobs, wire up dependencies, configure platforms, and validate the setup. Powered by the Azure AI Foundry and Azure OpenAI providers it ships alongside.
What you can orchestrate today
Every service connected to Polysync, regardless of vendor, is configured, discovered, and executed through the same interface.
Microsoft Azure
Google Cloud
Amazon Web Services
Secret Vaults
One subscription, one billing line for orchestration. Your Azure Marketplace subscription covers Polysync itself. The pipelines, notebooks, and functions Polysync orchestrates keep running on your own cloud account and are billed by your cloud provider as usual.
See it in action
An IDE-inspired studio designed for data engineers: light and dark themes, tree navigation, multi-tab editors, and visual DAGs throughout.
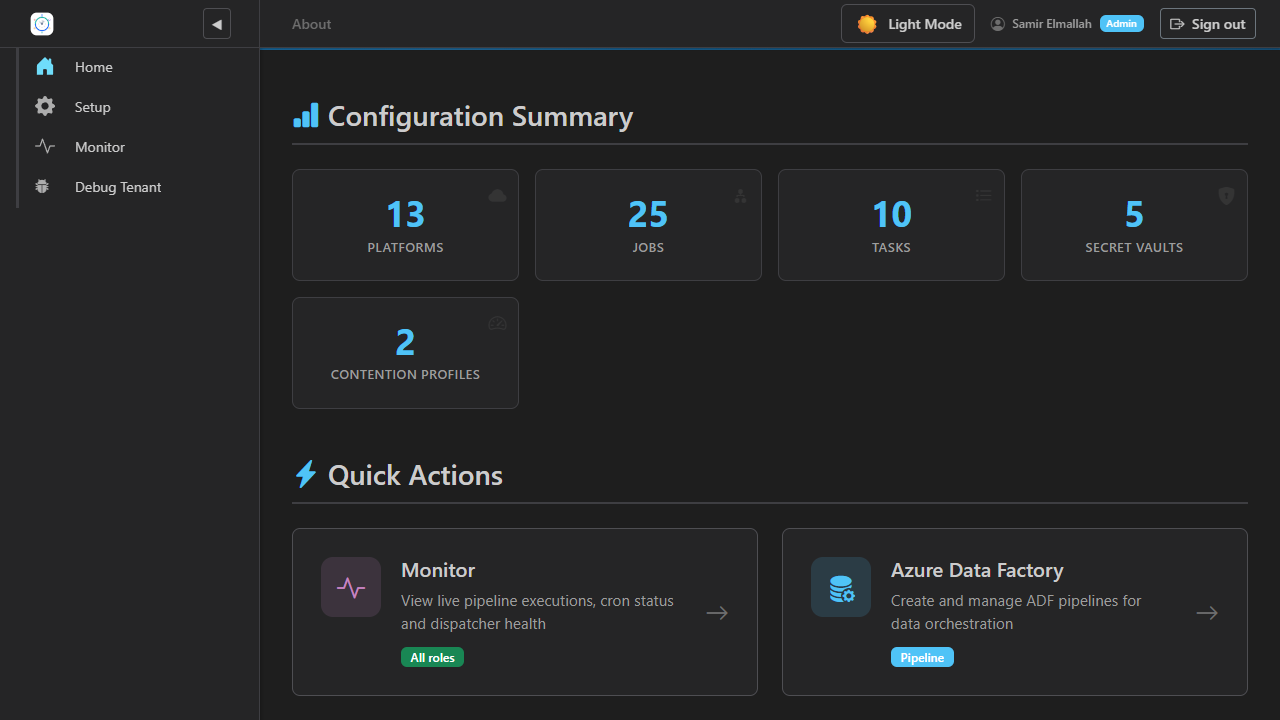
Quick actions and operational overview at a glance.
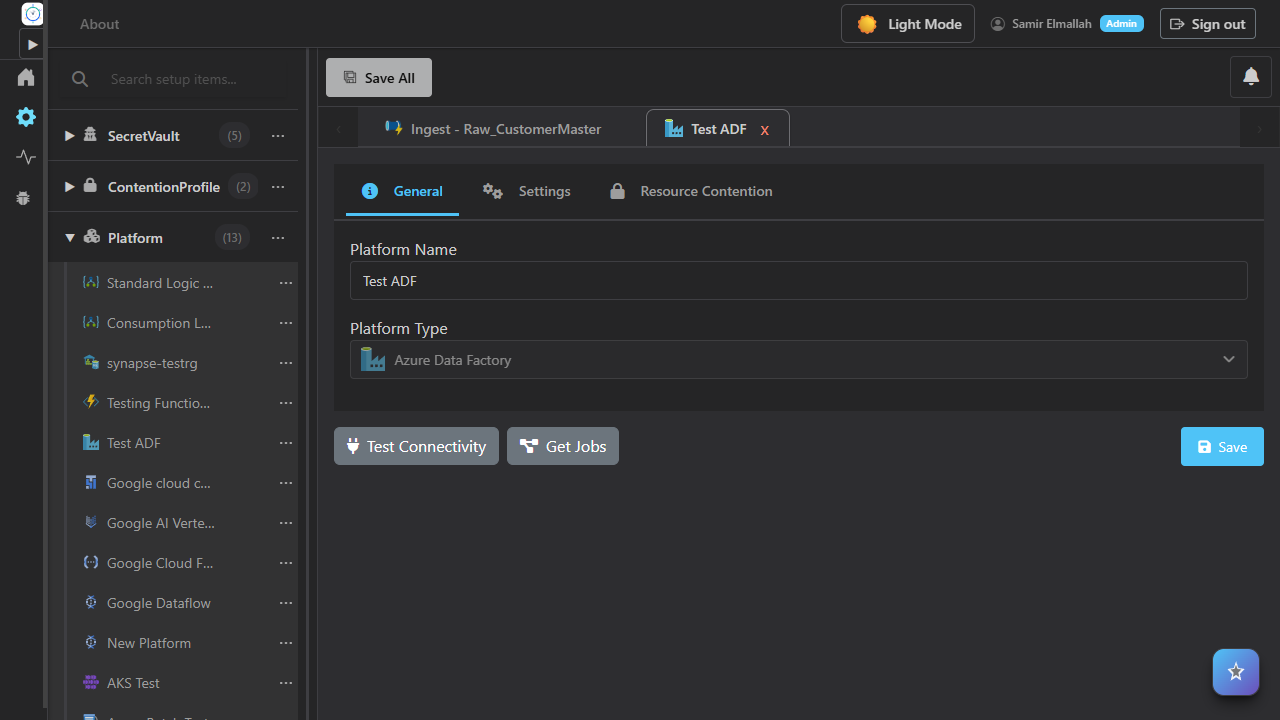
Searchable tree navigation with multi-tab editors.
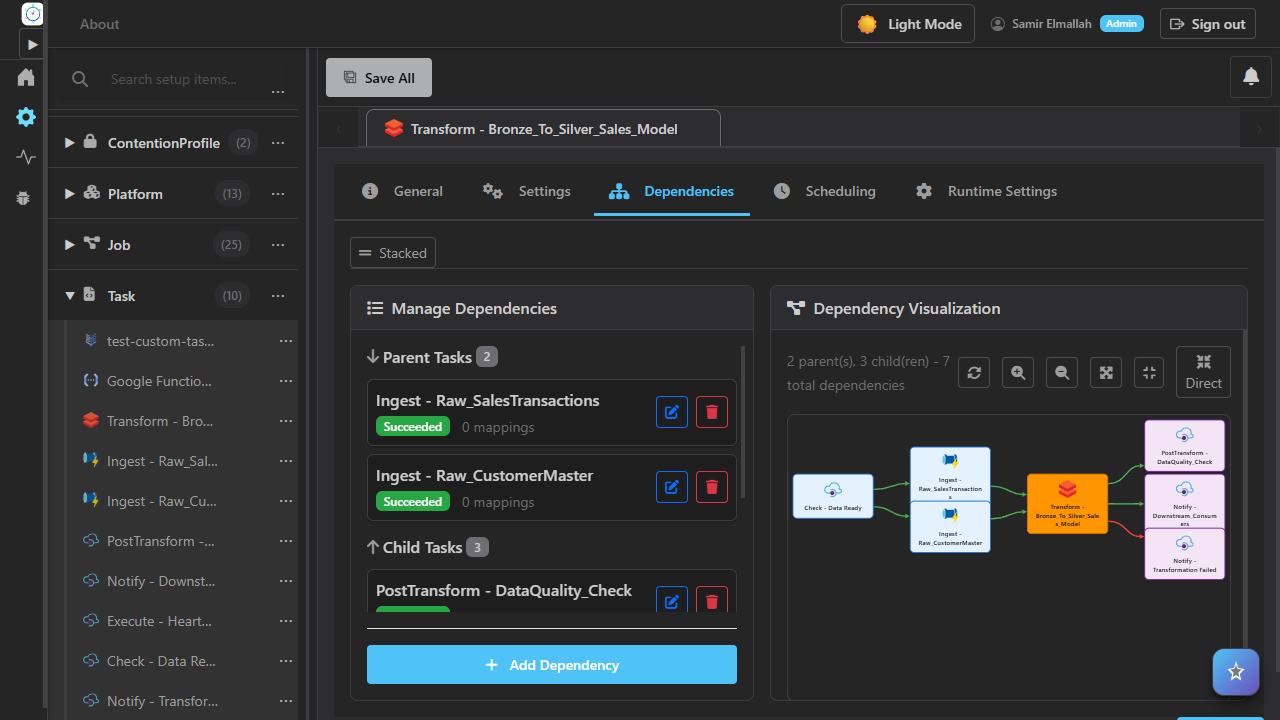
Interactive dependency graph with status colouring and zoom.
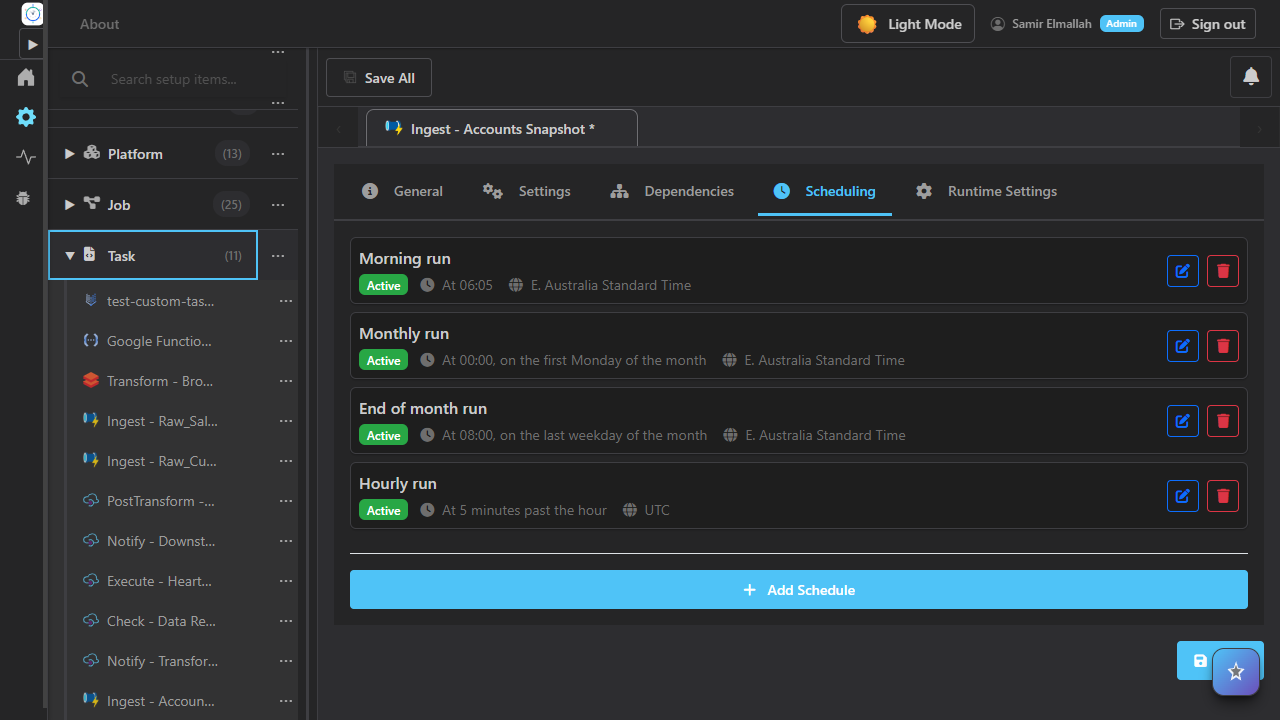
Cron editor with human-readable summaries and timezones.
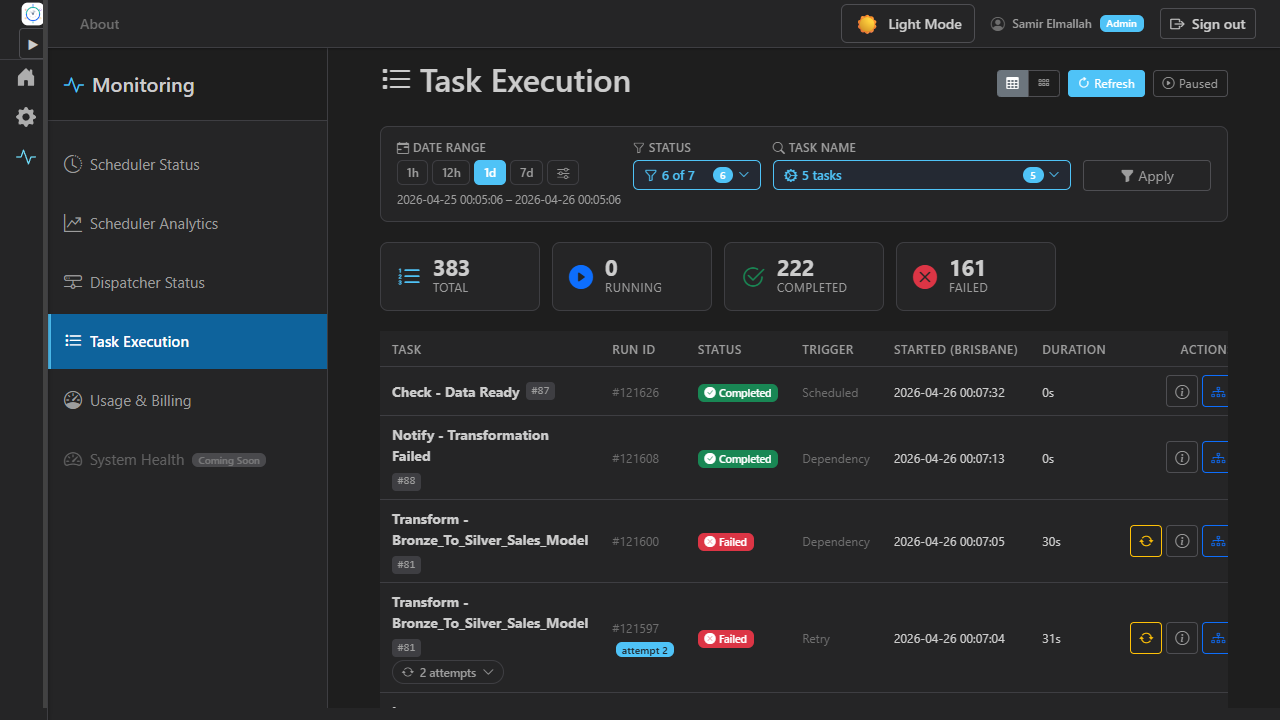
Execution tracking with filters, time ranges, and inline DAG.
System-aware light and dark themes across every editor.
What teams use Polysync for
Polysync is general-purpose orchestration, but a handful of patterns come up again and again across the data teams that adopt it.
Enterprise data warehouse loads
Chain ADF ingestion, Databricks transformations, and Synapse or Fabric publishing into a single nightly DAG. Cross-platform dependencies fire only when upstream tasks succeed, with retries and rate limits handled by the dispatcher.
ML and AI pipelines
Sequence feature engineering on Databricks, model training on Vertex AI or Azure AI Foundry, and batch scoring or generative-AI calls on Azure OpenAI, Functions, or AKS — passing parameters between stages without writing glue code.
Multi-cloud orchestration
Coordinate workloads that span Azure and Google Cloud from one DAG. A Cloud Composer job can trigger an ADF pipeline on success; output parameters flow across the cloud boundary automatically.
Reverse ETL and operational workflows
Trigger Logic Apps, Functions, or Dataflow jobs after analytics pipelines complete: sync data back to operational systems, send notifications, or kick off downstream business processes on a graph, not a clock.
Compliance and audit reporting
Every run, parameter, retry, and outcome is recorded per tenant in schema-isolated storage. Reconstruct exactly what ran, when, and with which inputs for SOX, APRA CPS 234, or internal audit reviews.
Consolidating fragmented schedulers
Replace ADF triggers, Databricks job schedules, Function timers, and cloud cron with a single scheduler that respects cross-service dependencies, concurrency caps, and rolling-window rate limits.
AWS to Azure migration in flight
Orchestrate Step Functions, Glue, Lambda, SageMaker, and AWS Batch alongside their Azure or Google Cloud counterparts in one DAG. Cut over service by service without rewriting orchestration.